Here is the Jupyter notebook. I have used the following Python libraries in this project: Pandas, Matplotlib, Folium, GeoPy, iPywidgets and Scikit-learn. Read on for a summary of the project.
Introduction:
Hong Kong is home to people from more than a hundred countries. Because of Hong Kong’s status as an international financial center with offices from many multinational corporations, it has a highly transient population of expat workers who are often blindsided by a city that defies most of its portrayals in media. One common issue is the relative absence of English as a medium of communication in comparison to an apparently similar city like Singapore. Not knowing Cantonese or Mandarin can cause quite a few difficulties in daily life; foremost among these is finding the right apartment in the right neighborhood.
Choosing a suitable neighborhood depends on varied factors including age and family status. In this project, we aim to characterize Hong Kong’s neighborhoods based on the types of businesses and amenities that are situated in those neighborhoods. We will then use this data to perform K-means clustering on the neighborhoods and come up with two useful widgets that identify similar neighborhoods with cheaper rents than a given one.
This analysis will be especially useful for foreign workers in Hong Kong who are trying to find a home in the city. It will also be useful for local Hong Kong residents who, despite their familiarity with the city, can still benefit from the data that we collect on more than 3000 venues and our analysis on said data.
Data:
We will use data from Spacious which is a property leasing website. This dataset has the names and average rent per square foot for 128 neighborhoods located within 18 districts in Hong Kong. We will supplement this data with the coordinates of each of these neighborhoods that we retrieved using the Python GeoPy module.

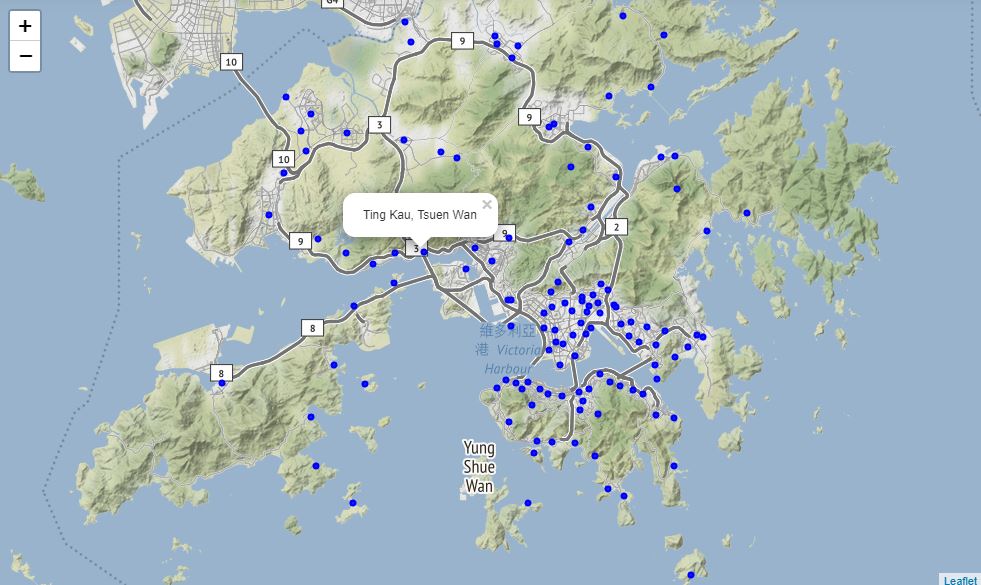
We can plot markers for these neighborhoods on a map of Hong Kong. Notice how the majority of Hong Kong’s land area is uninhabited, mountainous terrain and most of the developed area is situated next to the sea. This interactive map is created using the Folium module. Clicking on the location markers reveals the neighborhood’s name and district.
In addition to the dataset above, we will use data from Foursquare City Guide, commonly known as Foursquare, which is a local search-and-discovery service that provides recommendations of places to go near a user’s current location. We will utilize the Foursquare API to collect information on the venues within each neighborhood in order to characterize and profile each neighborhood. This neighborhood characterization can be achieved in a multitude of ways depending on the project goal and availability of data. For this project, we will characterize each neighborhood based on the entertainment, food, and shopping options located in that neighborhood. We made this choice because the intended target of this project is the young professional (who probably has no or a young family) living in Hong Kong. This means factors like school quality, building and population density, light or sound pollution, and community engagement won’t be too relevant even though they could be quite important for middle-aged and older people.
The data returned by Foursquare, after cleaning and processing, looks like this with each row giving information on a venue and its category/type. In total, we have information on 3034 venues from 257 different categories.

Methodology:
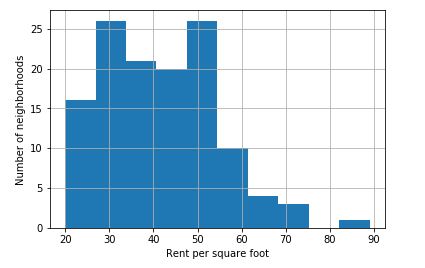
For exploratory data analysis, we start by analyzing the variable rent per square foot. The histogram below shows that the distribution is skewed to the right with the median falling in the HKD40 to HKD50 range.
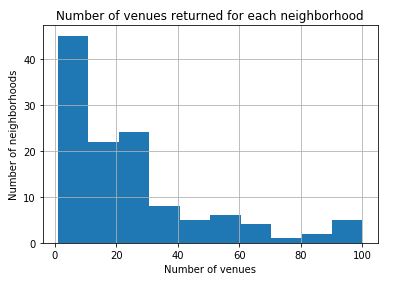
In the histogram below, we can see that the Foursquare data returned less than 10 venues for around 40 neighborhoods. While this probably indicates that these neighborhoods are secluded and residential, it could also suggest that more data is needed. This can be focused on in future iterations of this project. Also, there are 5 neighborhoods for which no results (i.e. venues) were returned from FourSquare. These neighborhoods have accordingly not been included in the following analysis.
Then, we start to transform our data to get it ready for the K-means clustering algorithm. We create indicator variables for all of our categories, group the rows by neighborhood and then standardize them to get, for every neighborhood, the proportion of venues in each category. These steps help us get the data in a form that’s easier to understand and enable us to develop a rough profile of each neighborhood.

We have successfully characterized each neighborhood by using the data from Foursquare. This means we can get to the most interesting part (at least for me) of the project, data modeling.
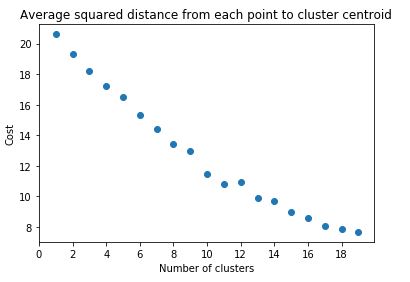
First, we’re going to run the K-means clustering algorithm for a range of cluster values in order to estimate the optimal number of clusters. In order to choose the optimal number of clusters, we can use a basic heuristic called the ‘elbow method’ which suggests that we should pick that number of clusters beyond which there is minimal improvement (i.e. decrease) in the cost function (the average squared distance from each point to cluster centroid). This would appear as a sudden decrease in the slope of the scatter plot above (i.e. an elbow in the plot). Based on the scatter plot below, we will opt for 10 clusters for the rest of this project.
After running the K-means algorithm once more using K=10, we assign cluster labels 0 to 9 to 122 neighborhoods. We dropped five neighborhoods earlier because Foursquare didn’t return any data on venues in those neighborhoods. These neighborhoods are assigned with the label 10 as a placeholder until better/more data becomes available.
Results:
We will now plot markers for all the neighborhoods on a map of Hong Kong with each marker colored according to its assigned cluster. Clicking on a marker will show you the neighborhood’s name and cluster label.
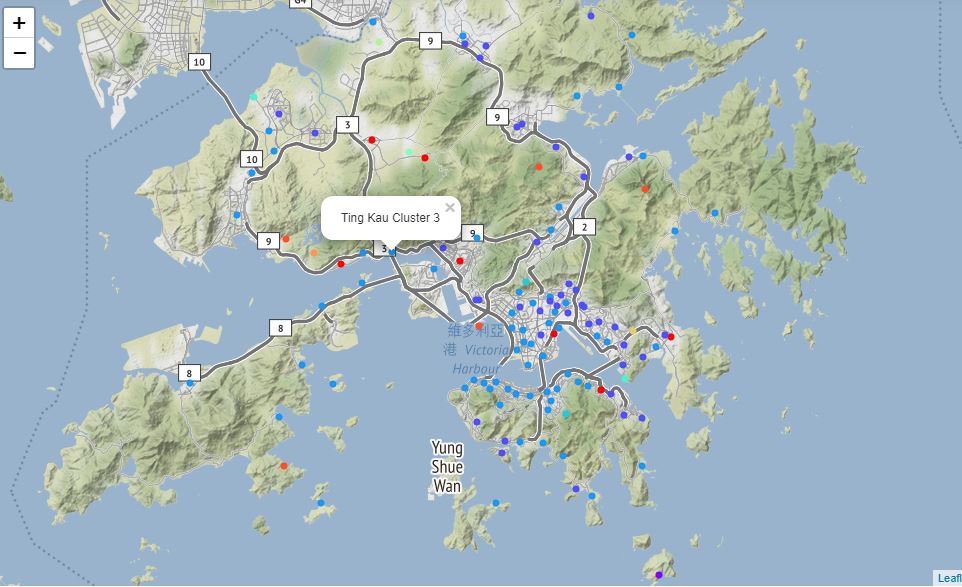
We can now examine any cluster that interests us and determine the discriminating venue categories that distinguish that cluster. Based on the defining categories, you can come up with a general profile of the cluster. For example, neighborhoods with cluster label 0 have a lot of Chinese restaurants. In the absence of data on neighborhood demographics, one can deduce that these neighborhoods are more popular among Hong Kong locals.
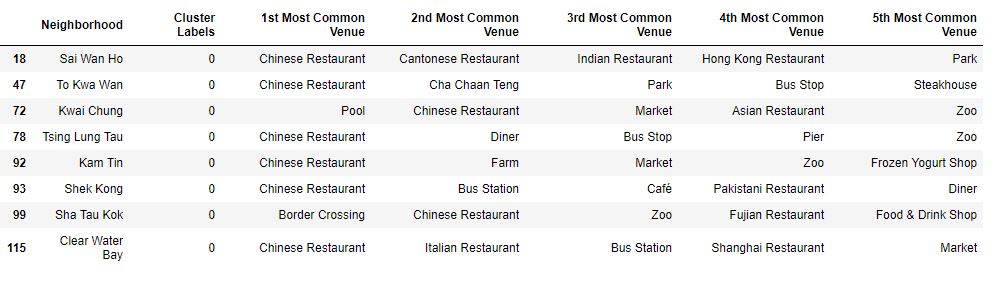
Cluster 3 appears to include neighborhoods that have a mix of local and non-local locations. Such informations points to the possibility of these neighborhoods having more diverse populations and locations than Cluster 0 which was described above. Similar analysis can be done for all the other clusters as well.
Now that we have characterized the neighborhoods, we can use our data in many different ways.
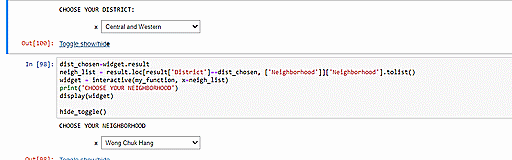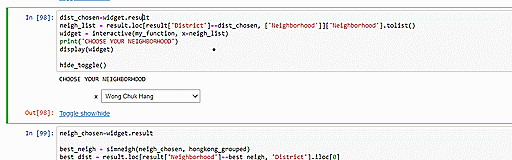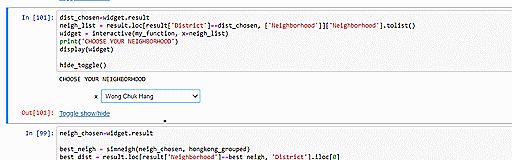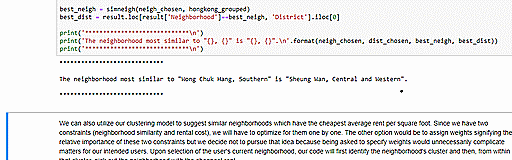
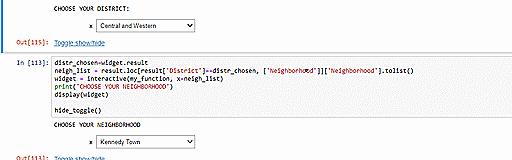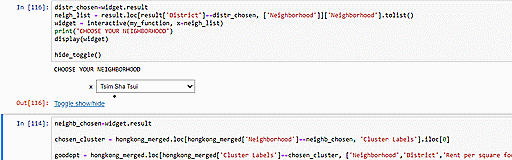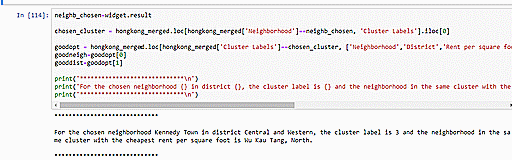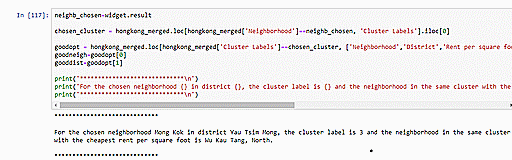
One application can be to use our data to identify most similar neighborhoods. For example, you can select your neigborhood in the following code cells and we will use our data to identify the most similar neighborhood based on Euclidean distance. Such information can be useful if you want to move to another neighborhood that is similar to the one in which you reside now. In the example below, we see that Sheung Wan is most similar to Wong Chuk Hang.
We can also utilize our clustering model to suggest similar neighborhoods which have the cheapest average rent per square foot. Since we have two constraints (neighborhood similarity and rental cost), we will have to optimize for them one by one. The other option would be to assign weights signifying the relative importance of these two constraints but we decide not to pursue that idea because being asked to specify weights would unnecessarily complicate matters for our intended users. Upon selection of the user’s current neighborhood, our code will first identify the neighborhood’s cluster and then, from within that cluster, pick out the neighborhood with the cheapest rent. In the example below, we see that choosing Mongkok as the input returns information on Mongkok’s cluster (i.e. Cluster 3) and the neighborhood with the cheapest rent in that cluster, Wu Kau Tang.
Discussion:
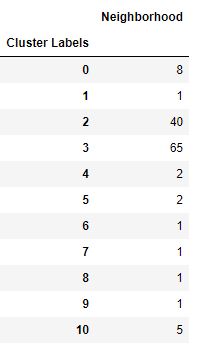
In the table above, we can see that clusters 2 and 3 are the most common. Some clusters have only one neighborhood which could indicate overfitting. Real-world knowledge of the dataset can assist in such a situation.
Based on my experience from living in Hong Kong for more than 6 years, I believe the clusters which include only one neighborhood are justified because of their unique locations and surroundings. Skeptical readers might wish to find on the map these unique neighborhoods to assuage any doubts.
Our analysis can be improved over time as the quality and quantity of data increases. Other variables that characterize a neighborhood such as population demographics, population density, crime statistics, etc., could be incorporated in a future analysis of the subject. Data from Google Maps on venues in each neighborhood is a promising option to complement the Foursquare data that we have now. Also, dynamic updating of our data on average rent prices from an online portal would be a more robust option than the static dataset that we are using now.